Disguise
December 12th, 2023
No comments
“The truth is the best disguise.”
”Die Wahrheit ist die beste Tarnung.”
Categories: Art
“The truth is the best disguise.”
”Die Wahrheit ist die beste Tarnung.”
“Light doesn’t cast a shadow. It is the object that casts the shadow.”
“Licht wirft keinen Schatten. Es ist das Objekt, das den Schatten wirft.”

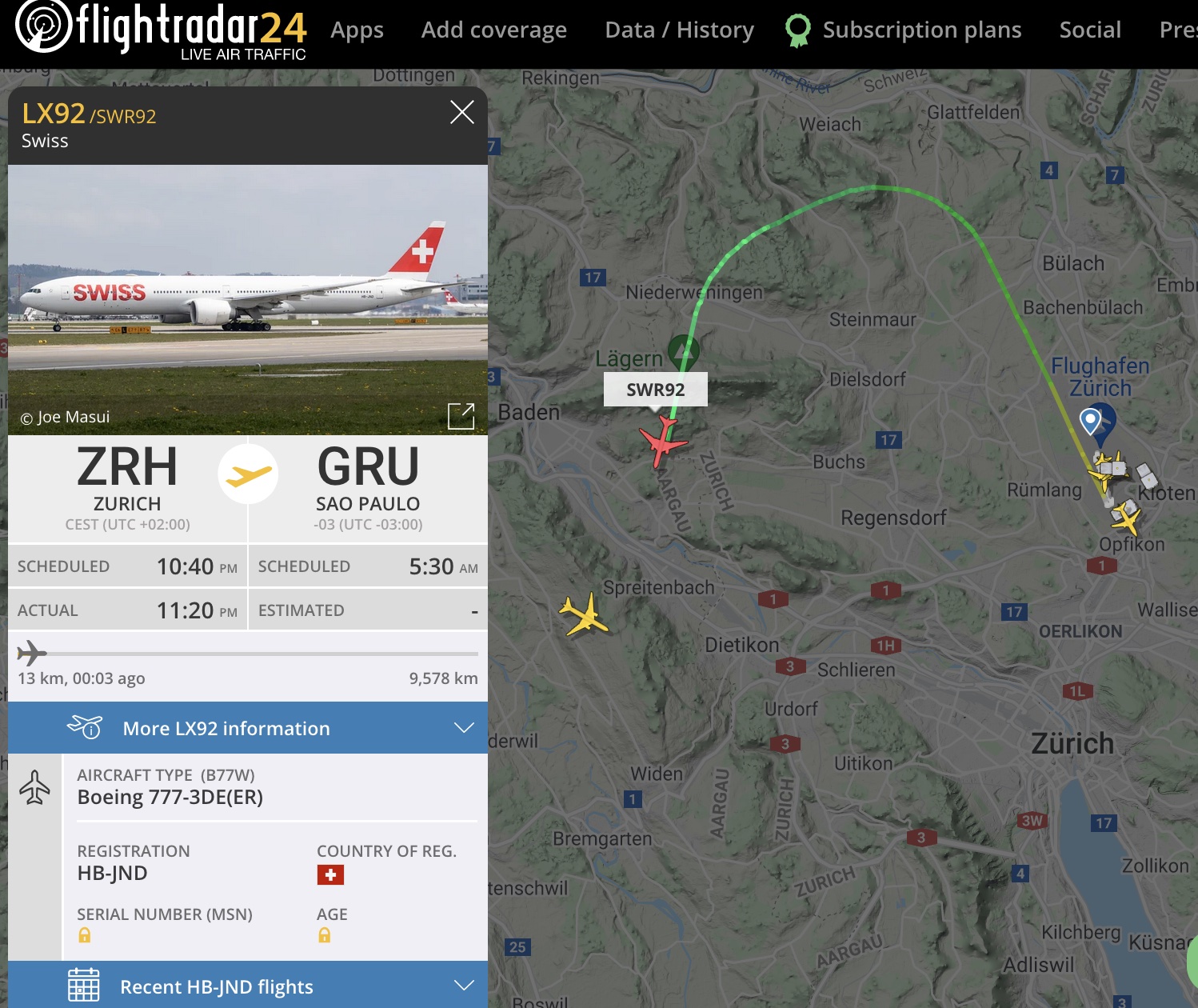
LX92 getting cleared for takeoff on runway 34, calls for a performance recalculation after indicated tailwind exceeds tolerance.
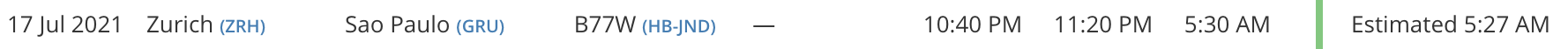
According to crew, the tripple-7 (HB-JND) is fully packed today, as yesterday’s LX92 flight was cancelled.

Here is the ATC recording and transcript
(sounds like first officer is doing voice, while captain is flying the plane)
LSZH tower 118.1 17JUL2021 2112 UTC
LSZH TWR: LX92 tower hello, your departure behind the next landing in about 4 minutes
LX92: Guete n’Abig, roger LX92
17JUL2021 2114 UTC
LSZH TWR: behind the landing A321 lineup runway 34 behind
LX92: behind the landing A321 lineup and wait 34 LX92
17JUL2021 2118 UTC
LSZH TWR: LX92 wind 090 degrees 2 knots runway 34 cleared for teakoff
LX92: runway 34 cleared takeoff LX92
…
LX92: LX92 (inaudible) approach(?), we have to calculate the takeoff performance new
LSZH TWR: ok LX92 ahm then takeoff clearance is cancelled hold position and report ready
LX92: hold position and we will call LX92
LSZH TWR: and just ehm say the reason – due to the wind?
LX92: affirm
LX92: (captain speaking) ahm we cannot accept for the moment any tailwind so as soon as wind is about 070 or less, then it’s ok for us.
LSZH TWR: ok, LX92 your wind south of runway 28 stays calm and about 090 2 knots
LX92: (captain speaking) ok, standby
LSZH TWR: which calculate (inaudible)
LX92: (captain speaking) give us 15 seconds then we are ready
17JUL2021 2120 UTC
LX92: LX92 ready for departure
LSZH TWR: LX92 merci wind remains 090 2 knots runway 34 cleared takeoff
LX92: cleared takeoff LX92
17JUL2021 2122 UTC
LSZH TWR: LX92 climb FL120 and report altitude
LX92: climb FL120 passing 2600 (ft) LX92
LSZH TWR: LX92 roger identified when passing FL80 proceed direct ROTOS
LX92: when passing FL80 direct ROTOS LX92
German WWI veteran describes killing a French soldier in a bayonet charge
Lee Kuan Yew, first Prime Minister of Singapore 1959 – 1990
[Update 23. October 2020]: Bongo Cat interactive (Source Code)
